 |
 |
|
 |
||
| Issue 20 | Spring 1998 | |
|
|
|
|
||
| Issue 20 | Spring 1998 | |
Social Research Update is published quarterly by the Department of Sociology, University of Surrey, Guildford GU2 7XH, England. Subscriptions for the hardcopy version are free to researchers with addresses in the UK. Apply by email to sru@soc.surrey.ac.uk.
Finding information on the World Wide Web
Stuart Peters is a Research Fellow in the Department of Sociology at the University of Surrey. He has been the Editorial and IT Officer for Sociological Research Online, a purely electronic journal available over the World Wide Web, since it was founded in 1995. He uses the Web extensively in his everyday work and has delivered numerous talks on how best to take advantage of this medium. His next project aims to consolidate the work he has done at Sociological Research Online by establishing a new electronic journal service.
To access a Web site, just type the address (or Universal Resource Locator, URL) into your browser. It will download and display the relevant page. Jump from one page to another by clicking on hyperlinks, usually underlined and displayed in a different colour to the body text, or represented graphically as buttons. Remember that few URLs have capital letters in them, particularly those of corporate home pages, but if you see them advertised with capitals, then make a note of these as Web addresses are case sensitive.
Guessing the URL of a Web site can be fairly straightforward once you know a little about Web addressing. Web addresses will always start with the ‘hypertext transfer protocol’ specification, http://. This will usually be followed by www and then a company or service name. This in turn is followed by ‘domain’ details which include a classification and a country code. Web sites based in the USA do not usually have a country code, but most other sites do; examples are ‘uk’, ‘au’, ‘ie’, ‘de’ and ‘fr’ for the United Kingdom, Australia, Ireland, Germany and France respectively. Classifications include ‘edu’ (or ‘ac’ in the UK) for academic sites; ‘co’ (or ‘com’ in the USA) for commercial or corporate sites; ‘org’ for non-profit sites and ‘gov’ for official government sites. With just this knowledge, it is easy to understand the site names in Figure 1.
The only limits to what information is available online are people’s imaginations and time. Commercial companies mount information about their services, products and ordering; universities put details of courses and departments online; and individuals make anything that interests them available. If you start with the premise that the information that you require is available then you will not usually be disappointed. Particularly pertinent to the researcher are academic texts, bibliographical information, job information, database resources and email discussion lists.
The keys to finding information on the Web are search engines. These exist at different levels and for different purposes. At one end, all Web browsers (such as Netscape Navigator and Internet Explorer) have a ‘find’ or ‘search’ facility which allows you to search the document being browsed for a particular string. Choose ‘search’ from the menu, or click on the search button, and enter part of a word. Click ‘find’ and your browser will take you to the first occurrence of that string in the document. At the other extreme are the many global search engines. These work by creating an index of every Web page that they come across. Users can then search (with no charge) for Web pages that match their search criterion. In between there are local search engines for particular sites, subject gateways, online databases and directories and a host of other tools to help you in your quest for information.
There are two sorts of global search facility: searchable indexes that aim to catalogue the contents of the entire Web, or ‘Search Engines’, and hierarchical content listings, sometimes called ‘Internet Guides’ or ‘Internet Directories’.
Search engines work by having software ‘robots’ or ‘spiders’ that traverse the Web. They download a page and then follow each link, downloading the next page. Each page is catalogued into one vast index and a simple Web interface allows users to search the index for pages that might contain the information they seek. The query interface usually just has one input line and a ‘submit’ or ‘search’ button. Don’t be put off by their simplicity -- Boolean and extended search facilities usually allow for extremely well defined searches (see Figure 2) and the more precise your search, the fewer, but more relevant, ‘hits’ will be returned. Each search engine has its own help page and a few minutes spent learning the particular syntax will be well rewarded.
AltaVista, Excite, Galaxy, Lycos and Yahoo are five of the most popular search engines, but there are many more. Try a number of them and decide which you like best. There are three main drawbacks to global searching. The first relates to the size of the index. Unless your search is very specific, it may result in millions of hits. Secondly, there is no measure of quality: all pages are catalogued. Finally the index is not always up to date and sometimes links returned by the search point to Web pages which no longer exist or have changed since they were catalogued.
AltaVista offers simple and advanced search interfaces. Operators and functions for the simple search appear below. Provided that your query is well structured and specific, the simple search is adequate for most purposes. AltaVista provide a good help facility at their web site. Avoid upper case letters in your searches as capitals must match exactly, whereas lower case will match upper and lower case.
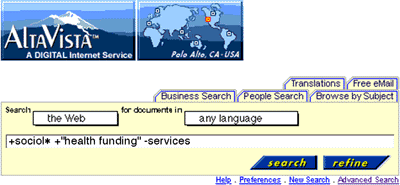
| Operators | ||||
| AltaVista Simple Search <http://www.altavista.digital.com/> | ||||
| * | wildcard | sociol* | matches sociological, sociology etc. | |
| + | include this term | +social +health +service | returns results with ALL words | |
| - | exclude this term | +social -service | must have ‘social’ but not ‘service’ | |
| “” | quote phrase | +“social services” | must include whole phrase | |
| Special Functions^ | ||||
title:text |
text must appear in title of page | |||
url:text |
text must appear in the page URL | |||
link:text |
text must appear in a hyperlink within a document | |||
image:text |
text must appear in the name of an image within the document | |||
| For example | ||||
image:elephant |
find images named ‘elephant’ | |||
link:socresonline |
find pages linking to Sociological Research Online | |||
| ^For other possibilities, see the help pages at AltaVista. | ||||
Internet directories are far less comprehensive than search engines, but because the entries are hand-picked, they reflect some measure of quality. These directories start with a small list of subject headings which lead down through a hierarchical index. The deeper you go, the more specifically defined are the pages that are listed. Most search engine sites also have this sort of directory guide.
Subject gateways are more specific than global engines. They contain databases of Web sites for a particular discipline. The information usually includes a brief description of each resource, some keywords and a link to the relevant site. Subject gateways are common for academic disciplines. Among the best for sociology are the Social Science Information Gateway (SOSIG), Sociosite and Socioweb. The advantage that these gateways have over search engines is that they list only reliable, high content sites and the smaller number of catalogued sites make searching less daunting.
Many other Web sites also list more informal links to related resources. Useful sociological Web pages include the link directories at Sociological Research Online, Sociology Corner and Michael Kearl’s Sociological Tour Through Cyberspace.
You may want to trace a particular person; the Web also has good facilities for finding email addresses. A number of online databases, including AltaVista People Search, Bigfoot and Yahoo allow you to search for people. As the databases are usually compiled by searching for email addresses from newsgroup postings, they often only contain the addresses of people who actively use news discussion groups. Increasingly ‘people sites’ offer links to yellow and white page databases but, disappointingly, these seem to include only telephone directories from the USA.
One of the most frustrating tasks for academics is seeking bibliographical information. Perhaps you want to find details of publications in particular areas, or you need publication details to complete your list of references. Once again the Web can come to your assistance!
Journal articles are best found through the citation indices. Most universities in the UK subscribe to Bath Information and Data Services (BIDS). This allows online access to the bibliographic databases of the Institute for Scientific Information (ISI) and the International Bibliography of the Social Sciences (IBSS) as well as other scientific and education databases. In order to search the databases you will require a user name and password which should be obtained from your university library. These databases contain full bibliographical information for millions of journal articles allowing you to carry out literature searches efficiently. The information stored includes title, author and journal details, and for articles catalogued by ISI, a full list of cited references.
Sometimes you will require book details. The best place to start would be your own university library catalogue. Failing this, you can search wider Web library catalogues such as the British Library’s OPAC 97 and COPAC, a national Online Public Access Catalogue which currently contains records from 10 university catalogues and continues to grow.
Other sources for current books are the leading Web-based bookshops, the Internet Bookshop and Amazon. Of course, these sites aim to sell books, but in addition they enable you to search their databases and retrieve publication details. Most publishers have their own Web sites which offer catalogues and information about new and forthcoming books. Guessing the URL for a publishing company is usually straightforward, try <http://www.PUBLISHER.co.uk> or <http://www.PUBLISHER.com>.
The Web is also a good source of freeware, shareware and demonstration software. Downloading software is usually as easy as searching a database and clicking links. Utilities to enhance productivity are perhaps the best examples of useful software, but you can also download cut-down versions of full commercial packages to ‘try before you buy’, and numerous ‘freeware’ packages which are often the product of funded research. You must take care to check any down-loaded packages for computer viruses, but provided that you go to reputable sites such as the Higher Educational National Software Archive (HENSA), the Virtual Software Library or the official Shareware Web site, you should not come across infected files. Commercial software houses regularly release ‘patches’ to update software which you already own. These patches may plug security holes, fix bugs or add new functions. The addresses of most software houses, such as Microsoft, Apple, Claris and Adobe, are of the form <http://www.COMPANY.com>. Capital letters are usually avoided.
The Web also allows access to like-minded people. No matter what information you require, or whom you want to meet, help is at hand. You can subscribe to email discussion lists about a very wide range of topics. All messages posted are sent to you and you can use the list to ask for help. Mailbase is a UK based service of mail lists covering areas aimed at academic teaching and research. Liszt is a comprehensive database of mailing lists covering thousands of different areas. You are usually advised to learn about ‘net-etiquette’ and to read lists of ‘Frequently Asked Questions’ (FAQs) before posting to groups. Further information about these topics is available from the Web sites mentioned.
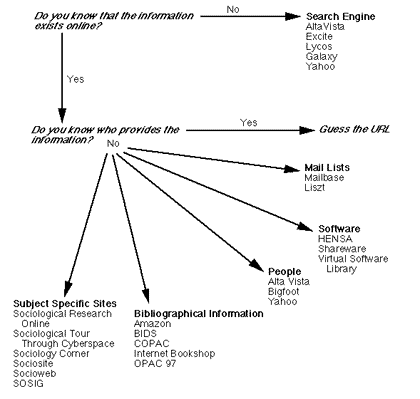
The information presented here can be summarised in a simple schematic (Figure 3). If you follow this for a few online searches, you will find that it soon becomes second nature and your ability to search for information over the Web should improve. Even if you have never used the Web before, you should find the prospect of a Netscape window less daunting. The more you practice searching on the Web, the more skilled you will become in structuring your queries. These should be as precise as possible. If you continue to receive too many hits, try more dedicated resources. Another point to remember is that search engines usually return results ranked in some order of matching, so that documents which satisfy your query in the title or near the top of the text will be returned before those that match lower down. Hits are usually returned in batches of ten and you need to click to the next page in order to view the following batch.
The Web is not simply a reference tool. There are plenty of other ways in which the Web can assist you with your work. You may decide to make some of your research available online by publishing your own papers on your university Web site; you may use the Web as a way of contacting people to participate in your research, even asking people to submit information to you online; or you may simply display information about yourself and your work in the hopes that individuals with similar interests might chance upon your pages and contact you. Space does not permit further discussion of these possibilities, but as the technology develops, new uses and possibilities will arise. If you are interested in pursuing these possibilities locally, contact your university’s computing services. Don’t forget, many tutorial sites are available online, it is just a matter of searching for them!
Social Research Update is published by:
Department of Sociology
Telephone: +44 (0) 1 483 300800
Fax: +44 (0) 1 483 689551
Edited by Nigel Gilbert.
Spring 1998 © University of Surrey
Permission is granted to reproduce this issue of Social Research Update provided that no charge is made other than for the cost of reproduction and this panel acknowledging copyright is included with all copies.